PHP
★ My current setup (end 2021 edition)
[AdSense-A]
My current setup (end 2021 edition)
After tweeting out a screenshot, it often get questions around which editor, font or color scheme I'm using. Instead of replying to those questions individually I've decided to just write down the settings and apps that I'm using.
IDE
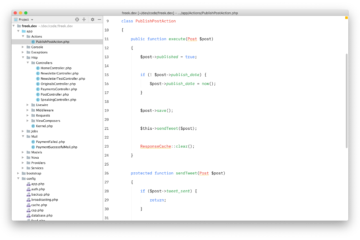
I mainly program PHP. Mostly I develop in PhpStorm. Here's a screenshot of it:
I'm using phpstorm-light-lite-theme which was handcrafted by my colleague Brent. The font used is Menlo.
Like seen in the screenshot I've hidden a lot of things of the UI of PhpStorm. I like to keep it minimal.
I like working using a light based theme. In some circles this is maybe a bit controversial. Watch this excellent video by my colleague Brent to learn what the benefits of using a light based theme are.
Mostly I work on Laravel projects. One of my favourite PhpStorm extensions is Laravel Idea, which can do stuff like autocomplete route names, request fields, and a whole lot more. It's paid, but definitely worth it.
Another PhpStorm plugin that I use is the Pest Plugin. It makes Pest a first class citizen in the IDE. This one is free.
Terminal
Here's a screenshot from my terminal.
All my terminal settings are saved in my dotfiles repository. If you want the same environment you follow the installation instructions of the repo.
My terminal of choice is iTerm2. I'm using the Z shell and Oh My Zsh.
The color scheme used is a slightly modified version of Solarized Dark. The font used is a patched version of Menlo. I'm using several hand crafted aliases and functions.
MacOS
I'm a day one upgrader of MacOS, so I'm always using the latest version. I also sometimes dare to use beta versions of MacOS when people are saying it's stable enough.
By default I hide the menu bar and dock. I like to keep my desktop ultra clean, even hard disks aren't allowed to be displayed there. On my dock there aren't any sticky programs. Only apps that are running are on there. I only have a stacks to Downloads and Desktop permanently on there. Here's a screenshot where I've deliberately moved my pointer down so the dock is shown.
I've also hidden the indicator for running apps (that dot underneath each app), because if it's on my dock it's running.
In my dotfiles repo you'll find my custom MacOS settings.
The spacey background I'm using was the default one on OSX 10.6 Snow Leopard. If you would like to use a class OSX background to, head over to this page at 512pixels.net.
{kind=link}
These are some of the apps I'm using:
To run projects locally I use Laravel Valet.
I couldn't live without Alfred. I'm using several workflows. First up is syn and assoc by Sebastian De Deyne, to help with naming things. phpstorm by bchatard to easily open recent PhpStorm projects. Last by not least I use the Laravel docs workflow by Till Krüss to easily search the Laravel docs.
To connect to S3, ftp (?) and sftp servers I use Transmit.
Local mail testing is done with Nodemailer. This handly little app install a local mailserver. In the apps you develop locally you can use that webserver to send mails. You can inspect all sent mails in Nodemailers beautiful, native UI.
Sometimes I need to run an arbitrary piece of PHP code. CodeRunner is an excellent app to do just that.
Paw is an amazing app to perform API calls.
I use BetterTouchTool to quickly resize windows quarter, half and full screen.
Databases are managed with TablePlus
My favourite cloud storage solution is Dropbox. All my personal documents are on there and at Spatie we use it extensively too.
If you're not using a password manager, you're doing it wrong. I use 1Password. Personal passwords are sync in a vault stored on Dropbox. For Spatie we have a team account.
All settings of my apps are backupped to Dropbox through Mackup. This is a fantastic piece of software that moves all your preferences to Dropbox and symlinks them.
I don't use Time Machine, my backups are handled with Backblaze.
Tweets are tweeted with Tweetbot.
I read a lot of blogs through RSS feeds in Reeder.
Mails are read and written in Mimestream. Unlike other email clients which rely on IMAP, Mimestream uses the full Gmail API. It super fast, and the author is dedicated using the latest stuff in MacOS. It's a magnificent app really.
My browser of choice is Safari, because of its speed and low power use. To block ads on certain sites I use the AdGuard plugin.
I like to write long blogposts in iA Writer
Calendars are managed in Fantastical 2
To create videos I use ScreenFlow.
I regularly stream stuff on YouTube. For that I use Ecamm Live
To pair program with anyone in my team, I use Tuple. The quality of the shared screen and sound is fantastic.
Even though I'm not a designer I sometimes have to edit images. For this I use Pixelmator.
GrandPerspective is a hidden gem that helps you determine how your disk space is being use used.
Outside of programming, I also record music. My DAW of choice is Ableton, I'm using the complete edition.
iOS
Here's a screenshot of my current homescreen.
I don't use folders and try to keep the number of installed apps to a minimum. There's also just one screen with apps, all the other apps are opened via search. Most of my time is spent in Safari, Pocket, Reeder and Tweetbot. Notifications and notification badges are turned off for all apps except Messages.
Here's a rundown of some of the apps currently on the homescreen:
1Password: my favourite password manager
Air Video HD: I find it much more reliable to sync videos to this one the stock Videos app. No iTunes needed.
Overcast: an excellent podcast client
Telegram: most of my geeky friends are on there
iA writer: to quickly write some stuff or take notes on the go
Clock: tick, tock, ...
Stripe: to quickly check how Flare and Oh Dear are doing financially
Mobile: horribly named, this the mobile banking app of my bank
Reeder: an RSS client
Slack: for communicating with my team and some other communities
Letterboxd: a pretty imdb. I use it to log every movie I watch
Railer: to easily look up the train schedules in Belgium
Pocket: my favourite read later service
Things: contains my to dos
Nuki: this controls the electronic doorlock at our office
There's no other screens setup. I use the App Library to hunt down any app I want to use that isn't on the home screen.
Hardware
Here's a picture of the desk I have at home.
Behind my desk there's a Hue Light Strip. When working in the evening, I like to set it to a moody color.
.
And this is how things look like when I stream.
.
I'm using a MacBook Pro 14" with an Apple M1 Pro processor, 16GB of RAM and 1T hard disk.
I usually work in closed-display mode. To save some desk space, I use a beautiful vertical Mac stand: the Twelve South BookArc.
Here's the hardware that is on my desk
a space grey wireless Apple Magic Keyboard with numeric keys
a space grey Apple Magic Trackpad 2
an LG 32UK550-B external monitor
a Livboj Wireless charger
two Elegato Air lights. These make a tremedous difference in quality when streaming
a Sure SM7B mic
when streaming, I use a Streamdeck to quickly switch scenes in Ecamm Live.
As a webcam I use a Sony a6400 camera with a Sigma 16mm 1.4 lens. It is connected to my computer via an Elgato Cam Link 4K. The camera also mounted on a Roda PSA1 boom arm, and when I'm not using it, the camera is behind my monitor.
To connect all external hardware to my MacBook I got a CalDigit TS3 plus. This allows me to connect the webcam / mic / USB Piano keyboard, and more to my MacBook with a single USB-C cable. That cable also charges the MacBook. Less clutter on the desktop, means I have more headspace, so I'm pretty happy with the TS3 plus.
I play music on a HomePod stereo pair. To stay in "the zone" when commuting and at the office I put on my QuietComfort 35 wireless headphones.
My current phone is an iPhone 13 Pro Max with 128 GB of storage.
Misc
At Spatie, we use Google Workspace to handle mail and calendars
High level planning at the company is done using Float
All servers I work on are provisioned by Forge.
The performance and uptime of those servers are monitored via Oh Dear.
To track exceptions in production, we use Flare
To send mails to our audience that is interested in our paid products, we use our homegrown Mailcoach.
If you want to know some more tools we use at Spatie, go over to the uses page on our company website.
In closing
Every year, I write a new version of the post. Here's the 2020 version.
If you have any questions on any of these apps and services, feel free to contact me on Twitter.